“CUDA out of memory” — nếu bạn đã từng train AI trên GPU, bạn gần như chắc chắn đã gặp lỗi này. Nó có nghĩa là GPU của bạn hết VRAM. Nhưng VRAM thực sự là gì? Nó khác RAM thường ra sao? Và quan trọng nhất: cần bao nhiêu VRAM cho tác vụ AI của bạn?
Bài viết này sẽ giải thích VRAM từ gốc, phân biệt các loại VRAM (GDDR6, GDDR7, HBM3), cung cấp bảng VRAM cần thiết cho từng tác vụ AI cụ thể, và hướng dẫn cách xử lý khi hết VRAM.
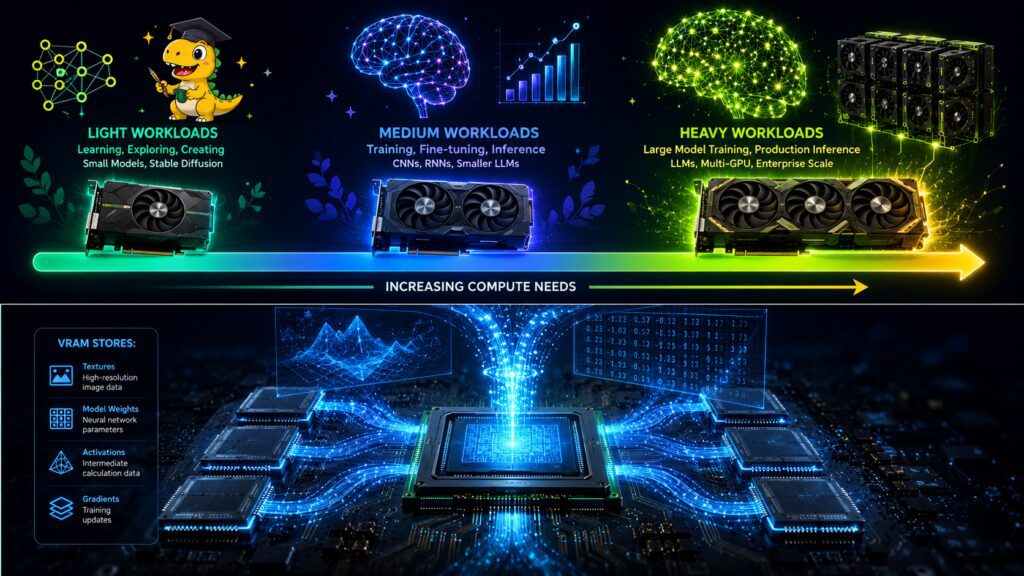
VRAM (Video Random Access Memory) là bộ nhớ chuyên dụng nằm trên card đồ hoạ (GPU), dùng để lưu trữ dữ liệu mà GPU đang xử lý — textures đồ hoạ, frame buffer, model weights AI và activations. VRAM có băng thông cực cao (500–3.350 GB/s), nhanh hơn RAM hệ thống 10–30 lần. Trong AI, VRAM quyết định bạn có thể load và train model nào — hết VRAM là training dừng lại.
VRAM là gì? Vai trò trên card đồ hoạ
VRAM (Video Random Access Memory) là bộ nhớ chuyên dụng được gắn trực tiếp trên card đồ hoạ, nằm ngay bên cạnh chip GPU. Nếu GPU là “nhà máy” xử lý, thì VRAM là “kho vật liệu” ngay sát nhà máy — chứa mọi thứ GPU cần để làm việc.
Hãy tưởng tượng GPU là một đầu bếp siêu nhanh. VRAM là mặt bàn bếp — nơi đầu bếp đặt nguyên liệu đang dùng. RAM hệ thống là tủ lạnh ở phòng kế bên. Nếu mặt bàn (VRAM) đủ lớn, đầu bếp làm việc cực nhanh. Nếu bàn nhỏ, đầu bếp phải liên tục chạy ra tủ lạnh (RAM) lấy đồ — chậm đi rất nhiều. Nếu cả bàn lẫn tủ lạnh đều hết chỗ — dừng nấu (CUDA out of memory).
VRAM lưu trữ tất cả dữ liệu mà GPU đang xử lý tại thời điểm hiện tại: textures đồ hoạ trong game, frame buffer (hình ảnh đã render), model weights trong AI training, gradient và activations trong deep learning.
VRAM vs RAM — khác nhau hoàn toàn

Nhiều người nhầm lẫn VRAM với RAM. Thực tế chúng phục vụ hai bộ xử lý khác nhau và không thể thay thế cho nhau:
| Tiêu chí | VRAM | RAM hệ thống |
|---|---|---|
| Phục vụ | GPU | CPU |
| Vị trí | Trên card đồ hoạ | Trên mainboard |
| Chức năng | Lưu dữ liệu đồ hoạ, AI training | Lưu dữ liệu OS, ứng dụng |
| Băng thông | 500–3.350 GB/s | 50–100 GB/s |
| Dung lượng phổ biến | 8–80 GB | 16–128 GB |
| Loại | GDDR6/GDDR7/HBM3 | DDR4/DDR5 |
| Nâng cấp | Không thể (phải mua card mới) | Có thể (thêm thanh RAM) |
| Giá | Rất đắt (gắn liền card) | Rẻ hơn nhiều |
Quy tắc kinh nghiệm: RAM hệ thống nên gấp đôi tổng VRAM GPU. Ví dụ: GPU RTX 4090 (24 GB VRAM) → cần tối thiểu 48 GB RAM hệ thống.
Các loại VRAM: GDDR6, GDDR7, HBM2e, HBM3

Không phải tất cả VRAM đều giống nhau. Có hai họ VRAM chính trên thị trường:
GDDR (Graphics DDR) — cho GPU consumer
GDDR6, GDDR6X và GDDR7 dùng trên GPU gaming/workstation (RTX 3060–5090). Dung lượng 8–32 GB, giá rẻ, dễ sản xuất. GDDR7 (mới nhất, trên RTX 5090) nhanh hơn GDDR6X khoảng 60%.
HBM (High Bandwidth Memory) — cho GPU datacenter
HBM2e và HBM3 dùng trên GPU datacenter (A100, H100). Dung lượng 40–80 GB, băng thông cực cao (HBM3: 3,35 TB/s — gấp 5 lần GDDR6). HBM đắt hơn nhiều nhưng tối ưu cho AI quy mô lớn.
| Loại VRAM | Băng thông | Dung lượng | GPU tiêu biểu | Phù hợp |
|---|---|---|---|---|
| GDDR6 | ~500 GB/s | 8–16 GB | RTX 3060, RTX 4060, T4 | Gaming, AI nhẹ, SD |
| GDDR6X | ~1.000 GB/s | 16–24 GB | RTX 4090 | AI vừa, render, training CNN |
| GDDR7 | ~1.600 GB/s | 24–32 GB | RTX 5090 | AI mạnh, GenAI, training |
| HBM2e | ~2.000 GB/s | 40–80 GB | A100 | Training LLM, HPC |
| HBM3 | ~3.350 GB/s | 80 GB | H100 | Training LLM lớn, multi-GPU |
Trong AI, VRAM lưu những gì?

Khi training một neural network, VRAM phải chứa đồng thời 4 loại dữ liệu:
- Model weights (tham số mô hình): Toàn bộ trọng số của neural network. Model 7B parameters ở FP16 chiếm khoảng 14 GB VRAM chỉ riêng weights.
- Activations: Giá trị trung gian tại mỗi layer trong forward pass, cần giữ lại để tính gradient trong backward pass. Đây thường là thành phần tốn VRAM nhất — có thể gấp 3–4 lần model weights.
- Gradients: Đạo hàm loss theo từng weight, dùng để cập nhật model. Kích thước bằng model weights.
- Optimizer states: Adam optimizer lưu 2 giá trị (momentum + variance) cho mỗi weight, gấp đôi kích thước model weights.
Tổng cộng, training một model 7B parameters (FP16) cần khoảng ~56–70 GB VRAM — vì sao A100 80GB hoặc H100 80GB là bắt buộc cho tác vụ này. Dùng LoRA fine-tune giảm xuống chỉ 16–24 GB vì không cần lưu full gradients và optimizer states.
Cần bao nhiêu VRAM? — Bảng theo tác vụ

| Tác vụ | VRAM tối thiểu | VRAM khuyến nghị | GPU gợi ý |
|---|---|---|---|
| Stable Diffusion (SD 1.5) | 6 GB | 8–12 GB | RTX 4060, RTX 3060 12GB |
| SDXL / Flux | 8 GB | 12–16 GB | RTX 4070, RTX 4080 |
| ComfyUI workflows phức tạp | 12 GB | 16–24 GB | RTX 4090, RTX 5090 |
| Inference BERT / ViT | 4 GB | 8 GB | T4, RTX 4060 |
| Inference LLM 7B (INT8) | 8 GB | 16 GB | RTX 4060 16GB, T4 |
| Inference LLM 13B | 16 GB | 24 GB | RTX 4090, RTX 5090 |
| Inference LLM 70B | 40 GB | 80 GB | A100 80GB, H100 |
| Fine-tune BERT/ViT (full) | 8 GB | 16 GB | T4, RTX 4060 |
| Fine-tune LLM 7B (LoRA) | 16 GB | 24 GB | RTX 4090, A100 40GB |
| Training LLM 7B (full) | 40 GB | 80 GB | A100 80GB, H100 |
| Training LLM 70B+ (multi-GPU) | 8×80 GB | 8×80 GB (640 GB tổng) | 8× H100 (DGX) |
| Render Blender (cảnh vừa) | 8 GB | 16–24 GB | RTX 4080, RTX 4090 |
| Render Blender (cảnh nặng 8K) | 16 GB | 24–48 GB | RTX 4090, RTX A6000 |
| Game 3D 1080p Ultra | 8 GB | 12 GB | RTX 4060 Ti |
| Game 3D 4K Ultra + RT | 12 GB | 16–24 GB | RTX 4090, RTX 5090 |
Đọc thêm: Thuê GPU train AI: T4, A100 hay H100?
Hết VRAM thì làm gì? 6 cách xử lý
Khi GPU hết VRAM, bạn sẽ gặp lỗi CUDA out of memory hoặc RuntimeError: CUDA error: out of memory. Dưới đây là 6 cách xử lý từ đơn giản đến nâng cao:
- Giảm batch size: Cách đơn giản nhất. Giảm batch size từ 32 xuống 16 hoặc 8 sẽ giảm đáng kể VRAM cần cho activations. Nhược điểm: training chậm hơn.
- Dùng mixed precision (FP16/BF16): Thêm
torch.cuda.amphoặcbf16=Truetrong config training. Giảm VRAM ~50% so với FP32 mà accuracy gần như không đổi. - Gradient checkpointing: Đánh đổi thời gian tính toán để tiết kiệm VRAM — chỉ lưu activations tại một số layer, tính lại phần còn lại khi backward. Tiết kiệm 60–70% VRAM cho activations.
- Dùng LoRA thay vì full fine-tune: LoRA chỉ train thêm các ma trận rank thấp (vài triệu parameters) thay vì toàn bộ model. Fine-tune LLM 7B chỉ cần 16 GB thay vì 80 GB.
- Gradient accumulation: Chia batch lớn thành nhiều micro-batch nhỏ, tích luỹ gradient rồi mới cập nhật. Hiệu quả tương đương batch lớn nhưng VRAM chỉ cần cho micro-batch.
- Thuê GPU có VRAM lớn hơn: Nếu đã tối ưu hết mà vẫn thiếu, giải pháp cuối cùng là thuê GPU Cloud với VRAM lớn hơn — A100 40/80 GB hoặc H100 80 GB. Thuê theo giờ (pay-as-you-go) giúp bạn chỉ trả cho thời gian cần GPU mạnh.
Luôn kiểm tra VRAM trước khi bắt đầu training: nvidia-smi hoặc torch.cuda.mem_get_info(). Tính toán VRAM cần thiết: model parameters × 2 bytes (FP16) × 4 (weights + grads + optimizer × 2) + activations. Nếu tổng vượt quá VRAM card, hãy dùng LoRA hoặc thuê GPU lớn hơn.
Câu hỏi thường gặp về VRAM
VRAM là gì?
VRAM (Video Random Access Memory) là bộ nhớ chuyên dụng nằm trên card đồ hoạ (GPU), dùng để lưu trữ dữ liệu mà GPU đang xử lý — textures, frame buffer, model weights AI, activations. VRAM có băng thông rất cao (500–3.350 GB/s) và không thể thay thế bằng RAM hệ thống.
Cần bao nhiêu VRAM để train AI?
Tuỳ tác vụ: Stable Diffusion cần tối thiểu 8 GB. Fine-tune BERT cần 8–16 GB. Fine-tune LLM 7B (LoRA) cần 16–24 GB. Training LLM 7B full cần 40–80 GB. Training LLM 70B+ cần multi-GPU 80 GB mỗi card. VRAM là yếu tố quyết định bạn có thể chạy model nào.
VRAM khác RAM như thế nào?
RAM phục vụ CPU, dùng cho OS và ứng dụng, băng thông 50–100 GB/s. VRAM phục vụ GPU, dùng cho đồ hoạ và tính toán AI, băng thông 500–3.350 GB/s. Chúng không thể thay thế nhau. Quy tắc: RAM hệ thống nên gấp đôi tổng VRAM.
GDDR6 và HBM3 khác nhau thế nào?
GDDR6/GDDR7 dùng trên GPU consumer (RTX), dung lượng 8–32 GB, giá rẻ. HBM2e/HBM3 dùng trên GPU datacenter (A100, H100), dung lượng 40–80 GB, băng thông cực cao nhưng đắt hơn rất nhiều. HBM tối ưu cho AI quy mô lớn.
Hết VRAM khi train AI thì sao?
Bạn sẽ gặp lỗi CUDA Out of Memory và training dừng lại. Cách khắc phục: giảm batch size, dùng mixed precision (FP16/BF16), gradient checkpointing, dùng LoRA thay full fine-tune, gradient accumulation, hoặc thuê GPU Cloud có VRAM lớn hơn.
Cần GPU có VRAM lớn để train AI?
Sunteco Cloud cho thuê GPU từ 8 GB đến 80 GB VRAM — trả theo giờ, hạ tầng Việt Nam.
- ✅ RTX 4060 (8 GB) đến H100 (80 GB)
- ✅ Pre-installed CUDA + PyTorch + Jupyter
- ✅ Thanh toán VNĐ, dùng thử miễn phí
- ✅ Hỗ trợ 24/7 tiếng Việt
Kết luận
VRAM là bộ nhớ chuyên dụng trên GPU, quyết định trực tiếp bạn có thể chạy được model AI nào. Trong deep learning, VRAM phải chứa đồng thời model weights, activations, gradients và optimizer states — vì vậy nhu cầu VRAM tăng rất nhanh theo kích thước model.
Hãy dùng bảng VRAM trong bài để chọn GPU phù hợp, áp dụng các kỹ thuật tối ưu (LoRA, mixed precision, gradient checkpointing) khi thiếu VRAM, và thuê GPU Cloud khi cần sức mạnh lớn hơn mà không muốn mua phần cứng.